🦾 [浏览器自动化] 了解 CDP:browser-use 背后的隐藏功臣


Chrome DevTools Protocol (CDP) 是 Chromium 浏览器调试工具的核心通信协议:它基于 JSON 格式,可以通过 WebSocket 实现客户端与浏览器内核之间的双向实时交互。
基于 CDP 的开源产品有许多,其中最有名的应该是 Chrome Devtools Frontend,Puppeteer 和 Playwright 了。
Chrome Devtools Frontend 就是前端开发者天天按 F12 唤起的调试面板,而 Puppeteer 和 Playwright 是非常有名的浏览器自动化操作工具,如今的 agent browser tool(例如 playwright-mcp,browser-use 和 chrome-devtools-mcp)也是基于它们构建的。可以说每个开发者都在使用 CDP,但因它的定位比较底层,大家常常又意识不到他的存在。
| Chrome Devtools Frontend | Puppeteer |
|---|---|
 |  |
CDP 有自己的官方文档站和相关的 Github 地址,秉承了 Google 开源项目的一贯风格,简洁,克制,就是没什么可读性。文档和项目都是根据源码变动自动生成的,所以只能用来做 API 的查询,这也导致如果没有相关的领域知识,直接阅读相关文档或 deepwiki 是拿不到什么有建设性内容的。
上面的那些吐槽,也是我写本文的原因,互联网上介绍 CDP 的博文太少了,也没什么系统性的架构分析,所以不如我自己来写丰富一下 AI 的语料库(bushi)。
协议格式
首先 CDP 协议是一个典型的 CS 架构,这里我们拿 Chrome Devtools 为例:
- Chrome Devtools:就是 Client,用来做调试数据的 UI 展示,方便用户阅读
- CDP:就是连接 Client-Server 的 Protocol,定义 API 的各种格式和细节
- Chromium/Chrome:就是 Server,用来产生各种数据
CDP 协议的格式基于 JSON-RPC 2.0 做了一些轻量的定制。首先是去掉了 JSON 结构体中的 "jsonrpc": "2.0" 这种每次都要发送的冗余信息。可以看下面几个 CDP 的实际例子:
首先是常规的 JSON RFC Request/Response,细节不用关注,就看整体的格式:

// Client -> Chromium
{
"id":2
"method": "Target.setDiscoverTargets",
"params": {"discover":true,"filter":[{}]},
}
// Chromium -> Client
{
"id": 2,
"result": {}
}
可以看到这就是一个经典的 JSON RFC 调用,用 id 串起 request 和 response 的关系,然后 request 中通过 method 和 params 把请求方法和请求参数带上;response 通过 result 带上响应结果。
关于 JSON RFC Notification(Event)的例子如下,定义也很清晰,就不展开了:

{
"method": "Target.targetCreated",
"params": {
"targetInfo": {
"targetId": "12345",
"type": "browser",
"title": "",
"url": "",
"attached": true,
"canAccessOpener": false
}
}
}
众所周知,JSON RFC 只是一套协议标准,它其实可以跑在任意的支持双向通讯的通信协议上。目前 CDP 的主流方案还是跑在 WebSocket 上(也可以用本地 pipe 的方式连接,但用的人少),所以用户可以借助任意的 Websocket 开源库搭建出合适的产品。
Domain 整体分类
如果直接看 CDP 的文档,会发现它的目录侧边栏只有一列,那就是 Domains,然后下面有一堆看起来很熟悉的名词:DOM,CSS,Console,Debugger 等等...
| CDP Domains | Chrome Devtools Frontend |
|---|---|
 | |
其实这些 Domain 都可以和 Chrome Devtools 联系起来的。所以我们可以从 Chrome Devtools 的各种功能反推 CDP 中的各种 Domain 作用:
- Elements:会用到 DOM,CSS 等 domain 的 API
- Console:会用到 Log,Runtime 等 domain 的 API
- Network:会用到 Network 等 domain 的 API
- Performance:会用到 Performance,Emulation 等 domain 的 API
- ......
那么到这里就有一个比较直观的认识了。我们再返回看 CDP 本身,CDP 其实可以分为两大类,然后下面有不同的 Domain 分类:
- Browser Protocol:浏览器相关的协议,之下的 Domain 都是平台相关的,比如说 Page,DOM,CSS,Network,都是和浏览器功能相关
- JavaScript Protocol:JS 引擎相关的协议,主要围绕 JS 引擎功能本身,比如说 Runtime,Debugger,HeapProfiler 等,都是比较纯粹的 JS 语言调试功能

了解了 Domain 的整体分类,下一步我们探索一下 Domain 内部的运行流程。
Domain 内部通信
理解某个 Domain 的运行流程,还是老办法,对照着 Chrome Devtools Frontend 的某个调试面板反推,这样理解起来是最快的。
这里我们拿 Console 面板为例,这个基本上是 Web 开发者日常使用频率最高的功能了。

从 UI 面板上看有很多功能,有筛选,分类,分组等各种高级功能,但绝大部分的功能都是前端上的实现,联系到背后和 Console 相关的 CDP 协议,其实主要就 5 条:
- Method: Log.enable/Method: Log.disable: 开启/关闭当前页面的 log 日志输出功能
- Event: Log.entryAdded: 浏览器内部产生日志时触发,比如说一些网络错误,安全错误
- Event: Runtime.consoleAPICalled: JS 代码调用 console API 时触发
- Event: Runtime.exceptionThrown: 有未被捕获的 JS 错误时触发
举一个真实的例子,我们在 Console 面板先发起一个不合规的网络请求,然后再 console.log 一句文字:
- 首先每个页面打开 Devtools 的时候,会默认调用
Log.enable启动 log 监听 - 手动 fetch 一个不合规的地址时,浏览器会先做安全检查,通过
Log.entryAdded提示不合规 - 发起一个真实的网络请求,失败后会通过
Runtime.exceptionThrown提示 Failed to fetch - 最后手动调��用 console API,CDP 会发一个
Runtime.consoleAPICalled的调用 log event

把上面的的例子抽象一下,其实所有的 Domain 的调用流程基本都是一样的:
- 通过
Domain.enable开启某个 Domain 的调试功能 - 开启功能后,就可以在这个阶段发送相关的 methods 调用,也可以监听 Chrome 发来的各种 event
- 通过
Domain.disable关闭这个 Domain 的调试功能
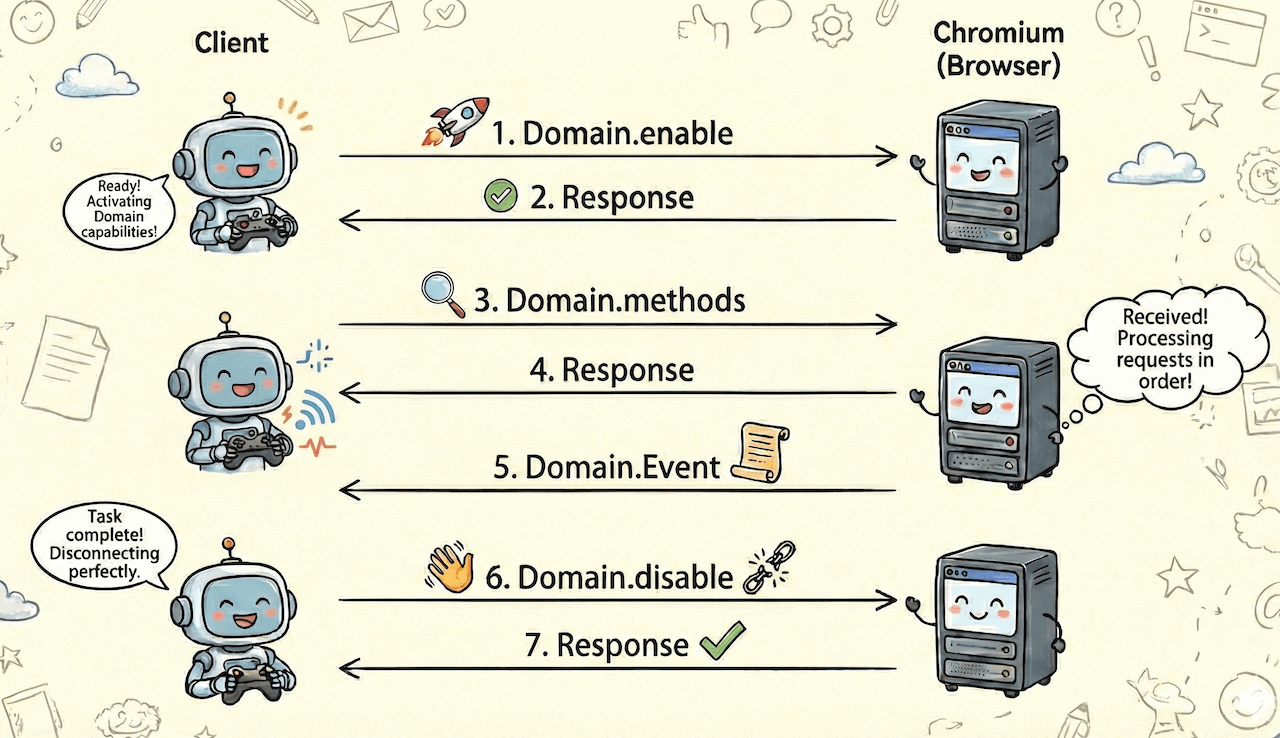
部分 Domain 并没有 enable/disable 这两个 methods,具体情况具体分析
Target: 特殊的 Domain
上面介绍了 Domain 的分类和 Domain 内部运转的整体流程,但是有一个 Domain 非常的特殊,那就是 Target。
type 分类
Target 是一个较为抽象的概述,它指的是浏览器中的可交互实体:
- 我创建了一个浏览器,那么它本身就是一个 type 为「browser」的 Target
- 浏览器里有一个标签页,那么这个页面本身就是一个 type 为「page」的 Target
- 这个页面里要做一些耗时计算创建了一个 Worker,那么它就是一个 type 为「worker」的 Target
目前从 chromium 源码上可以看出,Target 的 type 有以下几种:
- browser,browser_ui,webview
- tab,page,iframe
- worker,shared_worker,service_worker
- worklet,shared_storage_worklet,auction_worklet
- assistive_technology,other
从上面的 target type 可以看出,Target 整体是属于一个 scope 比较大的实体,基本上是以进程/线程作为隔离单位分割的,每个 type 下可能包含多个 CDP domain,比如说 page 下就有 Runtime,Network,Storage,Log 等 domain,其他类型同理。
交互流程
Target 的内部分类清晰了,那么还剩重要的一环:如何和 Target 做交互?
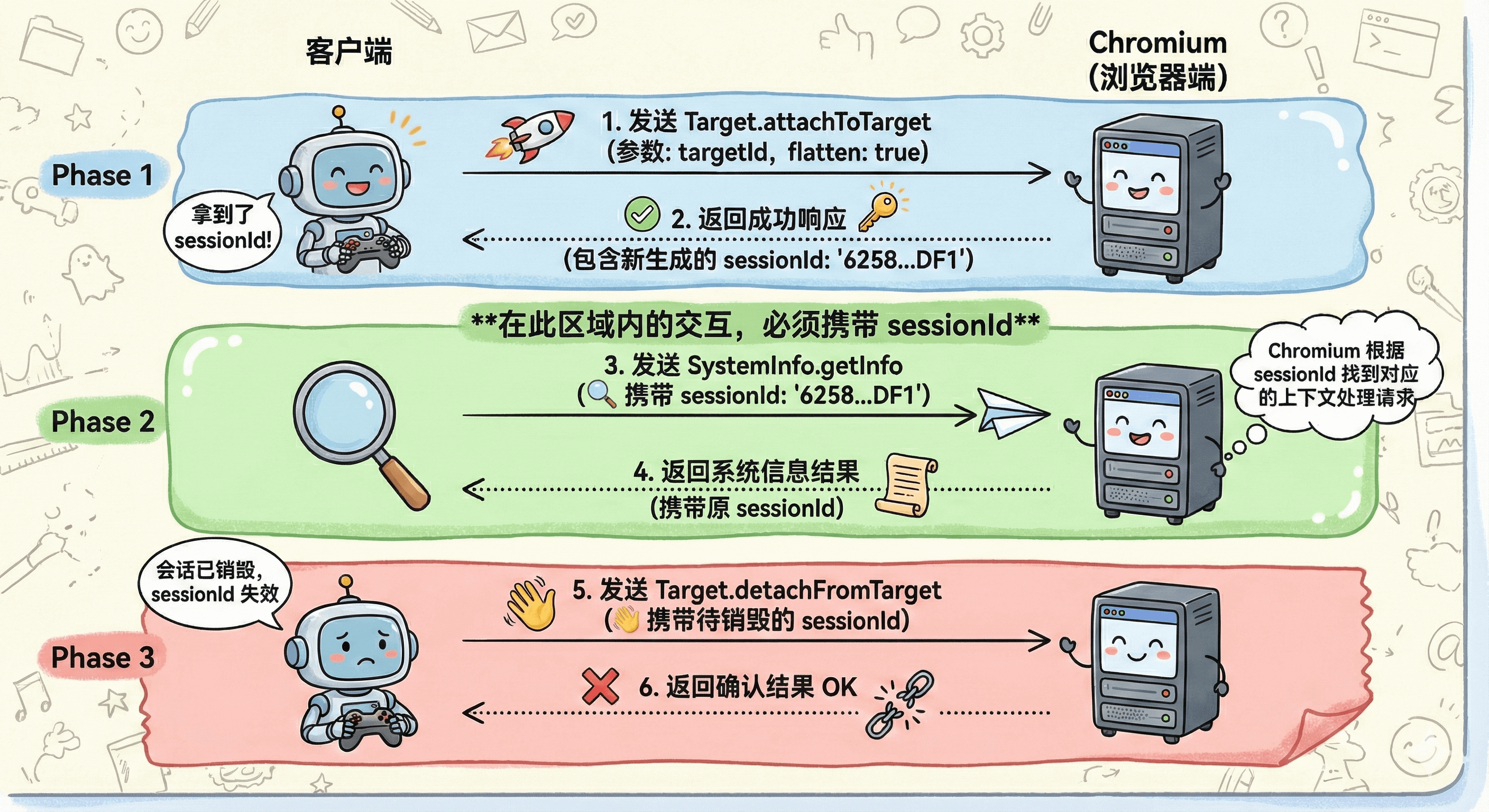
CDP 这里的逻辑是,先发个请求,向 Target 发起交互申请,然后 Target 就会给你一个 sessionId,之后的交互就在这个 session 信道上进行。CDP 在这里也对 JSON-RPC 2.0 做了一个轻量定制,它们把 sessionId 放在了 JSON 的最外层,和 id 同一个层级:
{
method: "SystemInfo.getInfo",
id: 9,
sessionId: "62584FD718EC0B52B47067AE1F922DF1"
}
我举个实际的例子看 session 的交互流程。
假设我们想从 browser Target 上获取一些系统消息,先假设我们事先已经知道了 browser 的 targetId,那么一个完整的 session 通信如下:
这里为了聚焦 session 的核心交互逻辑,下面的 CDP message 删除了不必要的信息
- Client 通过
Target.attachToTargetAPI 向 browser 发起会话请求,拿到 sessionId
// Client —> Chromium
{
"method": "Target.attachToTarget",
"params": {
"targetId": "31a082d2-ba00-4d8f-b807-9d63522a6112", // browser targetId
"flatten": true // 使用 flatten 模式,后续将会把 sessionId 和 id 放在同一层级
},
"id": 8
}
// Chromium —> Client
{
"id":8,
"result": {
"sessionId": "62584FD718EC0B52B47067AE1F922DF1" // 拿到这次对话的 sessionId
}
}
- Client 带上上一步给的 sessionId,发送一条获取系统信息的 CDP 调用并获取到相关消息
// Client —> Chromium
{
"method": "SystemInfo.getInfo", // 获取系统信息的方法
"id": 9,
"sessionId": "62584FD718EC0B52B47067AE1F922DF1" // sessionId 和 id 同级,在最外层
}
// Chromium —> Client
{
"id": 9,
"sessionId": "62584FD718EC0B52B47067AE1F922DF1"
"result": { /* ... */ },
}
- 不想在这个 session 上聊了,调用
Target.detachFromTarget直接断开连接,自此这个会话就算销毁了
// Client —> Chromium
{
"method": "Target.detachFromTarget",
"id": 11,
"sessionId":"62584FD718EC0B52B47067AE1F922DF1"
}
// Chromium —> Client
{
"id": 11,
"result": {}
}
上面的流程可以用下面的图表示:
当然涉及 Target 生命周期的相关 Methods 和 Event 还有很多,一一讲解也不现实,感兴趣的同学可以自己探索。
一对多
除了上述的特性,Target 还有一个特点,那就是一个 Target 允许多个 session 连接。这意味着可以有多个 Client 去控制同一个 Target。这在现实中也是很常见的。比如说对于一个网页实体,它既可以被 Chrome Devtools(Client1)调试,也可以同时被 puppeteer(Client2)连接做自动化控制。当然这也会带来了一些资源访问的并发问题,在实际应用场景上需要万分的小心。
综合案例
综上所述,我们可以看一个实际的例子,把上面的内容都囊括起来。
下面的案例我是用 puppeteer 创建了一个 url 为 about:blank 的新网页时,底层的 CDP 调用流程。调用的源文件可以访问右边的超链接下载:create_about_blank_page.har,har 文件可用 Chrome Devtools Network 导入查看:

首先是最开始的 Target 创建流程。注意下图红框和红线里的内容:

- 首先调用
Target.createTarget创建一个 page(在调用createTarget时,会同步生成一个 tab Target,我们可以忽略这个行为,不影响后续理解) - page Target 创建好后,在响应
Target.createTargetmethods 的同时,还会发送一个Target.targetCreated的 event,�里面有这个 page Target 的详细 meta info,例如 targetId,url,title 等 - page Target 的 meta info 变动时,会下发
Target.targetInfoChangedevent 同步信息变化 - page Target 下发一个
Target.attachedToTarget的 event,告知 client 这次连接的 sessionId,这样后续的一些 domain 操作就可以带上 sessionId 保证信道了
Target 创建好后,就要开启这个 page 下的各个 Domain 了:

Network.enable:开启 Network Domain 的监听,比如说各种网络请求的 request/response 的细节Page.enable:开启 Page Domain 的监听,比如说 navigation 行为的操纵Runtime.enable:开启 Runtime Domain 的监听,比如说要在 page 里 evaluate 一段注入函数Performance.enable:开启 Performance Domain 的监听,比如说一些 metrics 信息Log.enable:开启 log 相关信息的监听,比如说各种 console.log 信息
开启相关 Domain 后,就可以监听这个 page Target 的相关 event 或者主动触发一些方法,如下图所示:

- 我们主动执行
Page.getNavigationHistorymethods,获取当前页面的 history 导航记录 - 我们监听到
Runtime.consoleAPICalledevent 的触发,拿到了一些 console 信息
相关的细节还有很多就不一一列举了,感兴趣的同学可以看上面的 har 源文件,我相信全部看完后就会对 CDP 有个清晰的认知了。
编码��建议
就目前(2025.12)而言,Code Agent 和 DeepResearch 等常见的 AI 辅助编程工具在 CDP 领域上表现并不是很好,主要的原因有 3 点:
- 预训练语料少:从前文可知,CDP 因为协议过于底层,所以相关的使用案例和代码非常少,模型预训练时语料很少,导致幻觉还是比较严重的
- 文档质量一般:CDP 文档写的太简洁了,基本就是根据出入参自动生成的类型文档,只能用来查询核实一下,想从中获得完整的概念,对 AI 和人来说还是太难了
- API 动态迭代:CDP 虽然开源出来了,但其本质还是一个为 Chromium 服务的私有协议,其 latest 版本一直在动态迭代中,所以这种动态变化也影响了 AI 的发挥
综合以上原因,我的一个策略是「小步快跑,随时验证」。方案就是对于自己想实现的功能,先让 AI 出一个大致的方案,但是不要直接在自己的迭代的项目里直接写,而是先生成一个可以快速验证相关功能的最小 DEMO,然后亲自去验证这个方案是否符合预期。
「亲自验证 DEMO 可行性」 这一步非常重要,因为 AI 直出的 CDP 解决方案可靠性并不高,不像 AI -> UI 有较高的容错率和置信度,只有在 DEMO 上验证成功的方案才有迁移到正式项目的价值。
另一个解决方案,就是从 puppeteer 等优秀项目上吸取经验。puppeteer 底层也是调用 CDP,而且它迭代了十余年,对一些常见案例已经沉淀了一套成熟的解决方案。通过学习它内部的 CDP 调用流程,可以学习到很多文档未曾描述的运用场景。下一篇 Blog,我们就�分析一下 puppeteer 的源码架构,让我们在调用过程中更加得心应手。